本文介绍如何整合前文实现的 MCP 服务端和 MCP 客户端(基于 SSE 传输协议),实现数学运算智能问答应用,该应用可实现以下功能:
-
- 用户与大模型的交互式对话。
-
- 列出 MCP 服务端可用的全部工具 tool 的信息。
-
- 大模型根据用户的问题,判断是否要调用工具。若要调用工具,大模型给出工具调用的请求参数。
-
- 通过 MCP 客户端,对 MCP 服务端进行工具调用请求,并获取工具调用结果。
-
- 大模型结合工具调用结果,回答用户的问题。
本文的主要内容如下:
-
- 主要对象关系、应用实现流程步骤
-
- 系统提示词(应用的关键,指导 LLM 如何与 MCP 服务进行交互)
-
- 编码实现
-
- 效果验证
Ollama-python:工具赋能大模型,以数学运算智能问答应用为例,详细介绍了如何基于 Function Call 实现数学运算智能问答应用,读者可以对比阅读,比较 MCP 与 Function Call 两者的特点。
主要对象关系、应用实现流程步骤
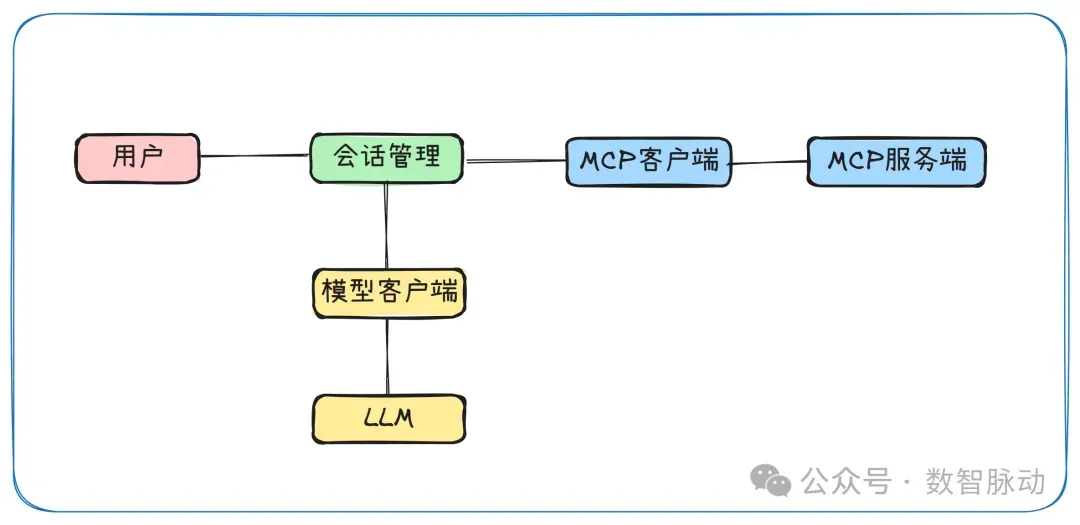
主要对象关系
- 会话管理:
- 处理用户输入并展示AI响应
- 维护对话历史记录
- 协调LLM和MCP客户端之间的交互
- 解析LLM响应中的工具调用请求
- 处理工具执行结果并将其反馈给LLM
- 模型客户端:与大语言模型API通信的客户端。主要职责:封装与 LLM 服务的API交互;发送对话历史到LLM并获取响应。
- MCP客户端:与MCP服务端通信的客户端
- MCP服务端:提供工具服务的后端服务器
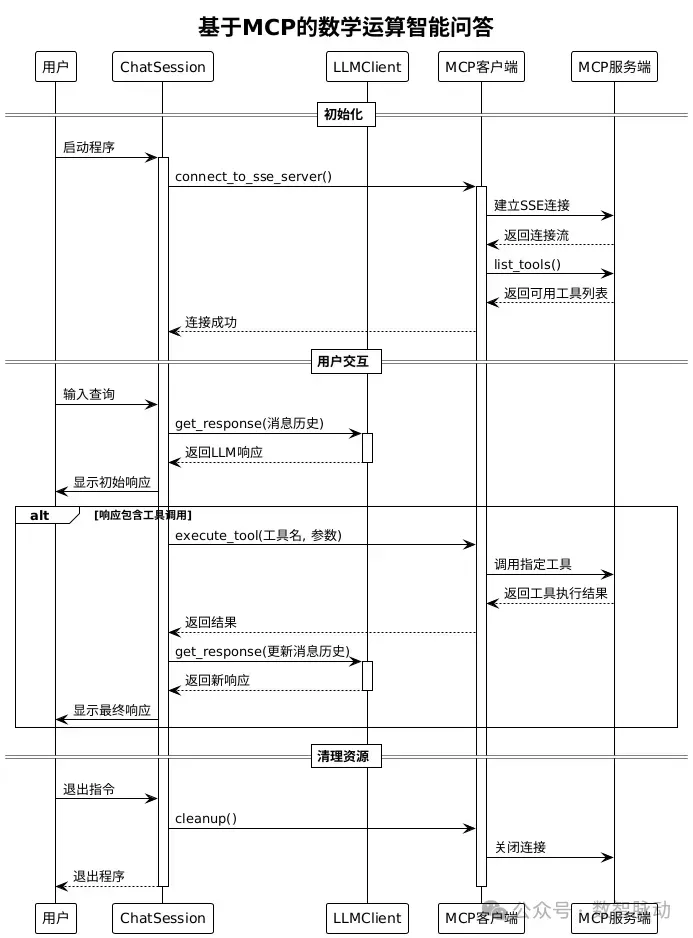
流程步骤
- 初始化阶段 - 建立MCP连接并获取工具列表
- 交互循环 - 用户输入,LLM响应,工具调用处理
- 工具调用处理 - 当LLM返回工具调用指令时的处理流程
- 清理资源 - 程序退出时的资源清理
系统提示词
系统提示词是整个应用的关键部分,它指导 LLM 如何与 MCP 服务进行交互。以下是经过笔者针对本应用的经过多次调试的系统提示词:
# 系统提示,指导LLM如何使用工具和返回响应
system_message = f'''
你是一个智能助手,严格遵循以下协议返回响应:
可用工具:{tools_description}
响应规则:
1、当需要计算时,返回严格符合以下格式的纯净JSON:
{{
"tool": "tool-name",
"arguments": {{
"argument-name": "value"
}}
}}
2、禁止包含以下内容:
- Markdown标记(如```json)
- 自然语言解释(如"结果:")
- 格式化数值(必须保持原始精度)
- 单位符号(如元、kg)
校验流程:
✓ 参数数量与工具定义一致
✓ 数值类型为number
✓ JSON格式有效性检查
正确示例:
用户:单价88.5买235个多少钱?
响应:{{"tool":"multiply","arguments":{{"a":88.5,"b":235}}}}
错误示例:
用户:总金额是多少?
错误响应:总价500元 → 含自然语言
错误响应:```json{{...}}``` → 含Markdown
3、在收到工具的响应后:
- 将原始数据转化为自然、对话式的回应
- 保持回复简洁但信息丰富
- 聚焦于最相关的信息
- 使用用户问题中的适当上下文
- 避免简单重复使用原始数据
'''
编码实现
LLMClient
class LLMClient:
"""LLM客户端,负责与大语言模型API通信"""
def __init__(self, model_name: str, url: str, api_key: str) -> None:
self.model_name: str = model_name
self.url: str = url
self.client = OpenAI(api_key=api_key, base_url=url)
def get_response(self, messages: list[dict[str, str]]) -> str:
"""发送消息给LLM并获取响应"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=messages,
stream=False
)
return response.choices[0].message.content
ChatSession:
class ChatSession:
"""聊天会话,处理用户输入和LLM响应,并与MCP工具交互"""
def __init__(self, llm_client: LLMClient, mcp_client: MCPClient, ) -> None:
self.mcp_client: MCPClient = mcp_client
self.llm_client: LLMClient = llm_client
asyncdef cleanup(self) -> None:
"""清理MCP客户端资源"""
try:
await self.mcp_client.cleanup()
except Exception as e:
logging.warning(f"Warning during final cleanup: {e}")
asyncdef process_llm_response(self, llm_response: str) -> str:
"""处理LLM响应,解析工具调用并执行"""
try:
# 尝试移除可能的markdown格式
if llm_response.startswith('```json'):
llm_response = llm_response.strip('```json').strip('```').strip()
tool_call = json.loads(llm_response)
if"tool"in tool_call and"arguments"in tool_call:
# 检查工具是否可用
tools = await self.mcp_client.list_tools()
if any(tool.name == tool_call["tool"] for tool in tools):
try:
# 执行工具调用
result = await self.mcp_client.execute_tool(
tool_call["tool"], tool_call["arguments"]
)
returnf"Tool execution result: {result}"
except Exception as e:
error_msg = f"Error executing tool: {str(e)}"
logging.error(error_msg)
return error_msg
returnf"No server found with tool: {tool_call['tool']}"
return llm_response
except json.JSONDecodeError:
# 如果不是JSON格式,直接返回原始响应
return llm_response
asyncdef start(self, system_message) -> None:
"""启动聊天会话的主循环"""
messages = [{"role": "system", "content": system_message}]
whileTrue:
try:
# 获取用户输入
user_input = input("用户: ").strip().lower()
if user_input in ["quit", "exit", "退出"]:
print('AI助手退出')
break
messages.append({"role": "user", "content": user_input})
# 获取LLM的初始响应
llm_response = self.llm_client.get_response(messages)
print("助手: ", llm_response)
# 处理可能的工具调用
result = await self.process_llm_response(llm_response)
# 如果处理结果与原始响应不同,说明执行了工具调用,需要进一步处理
while result != llm_response:
messages.append({"role": "assistant", "content": llm_response})
messages.append({"role": "system", "content": result})
# 将工具执行结果发送回LLM获取新响应
llm_response = self.llm_client.get_response(messages)
result = await self.process_llm_response(llm_response)
print("助手: ", llm_response)
messages.append({"role": "assistant", "content": llm_response})
except KeyboardInterrupt:
print('AI助手退出')
break
main 函数:
async def main():
"""主函数,初始化客户端并启动聊天会话"""
mcp_client = MCPClient()
# 初始化LLM客户端,使用通义千问模型
llm_client = LLMClient(model_name='qwen-plus-latest', api_key=os.getenv('DASHSCOPE_API_KEY'),
url='https://dashscope.aliyuncs.com/compatible-mode/v1')
try:
# 连接到MCP服务器
await mcp_client.connect_to_sse_server('http://localhost:8080/sse')
chat_session = ChatSession(llm_client=llm_client, mcp_client=mcp_client)
# 获取可用工具列表并格式化为系统提示的一部分
tools = await mcp_client.list_tools()
dict_list = [tool.__dict__ for tool in tools]
tools_description = json.dumps(dict_list, ensure_ascii=False)
# 系统提示,指导LLM如何使用工具和返回响应
system_message = f'''
你是一个智能助手,严格遵循以下协议返回响应:
可用工具:{tools_description}
响应规则:
1、当需要计算时,返回严格符合以下格式的纯净JSON:
{{
"tool": "tool-name",
"arguments": {{
"argument-name": "value"
}}
}}
2、禁止包含以下内容:
- Markdown标记(如```json)
- 自然语言解释(如"结果:")
- 格式化数值(必须保持原始精度)
- 单位符号(如元、kg)
校验流程:
✓ 参数数量与工具定义一致
✓ 数值类型为number
✓ JSON格式有效性检查
正确示例:
用户:单价88.5买235个多少钱?
响应:{{"tool":"multiply","arguments":{{"a":88.5,"b":235}}}}
错误示例:
用户:总金额是多少?
错误响应:总价500元 → 含自然语言
错误响应:```json{{...}}``` → 含Markdown
3、在收到工具的响应后:
- 将原始数据转化为自然、对话式的回应
- 保持回复简洁但信息丰富
- 聚焦于最相关的信息
- 使用用户问题中的适当上下文
- 避免简单重复使用原始数据
'''
# 启动聊天会话
await chat_session.start(system_message)
finally:
# 确保资源被清理
await chat_session.cleanup()
if __name__ == "__main__":
asyncio.run(main())
效果验证
- 运行 mcp 服务端(mcp 服务端,可阅读前文:)
- 本应用运行效果:
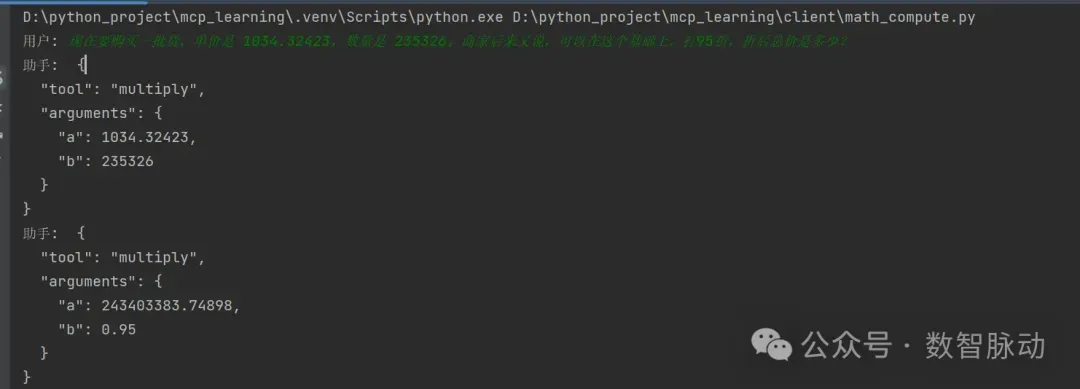
模型可以根据用户的问题,正确地判断并调用工具,根据工具的调用结果,回答用户的问题:
D:\python_project\mcp_learning\.venv\Scripts\python.exe D:\python_project\mcp_learning\client\math_compute.py
用户: 现在要购买一批货,单价是 1034.32423,数量是 235326。商家后来又说,可以在这个基础上,打95折,折后总价是多少?
助手: {
"tool": "multiply",
"arguments": {
"a": 1034.32423,
"b": 235326
}
}
助手: {
"tool": "multiply",
"arguments": {
"a": 243403383.74898,
"b": 0.95
}
}
助手: 折后总价是231233214.56153098。
用户: 我和商家关系比较好,商家说,可以在上面的基础上,再返回两个点,最后总价是多少?
助手: {
"tool": "multiply",
"arguments": {
"a": 231233214.56153098,
"b": 0.98
}
}
助手: 最终总价是226608550.27030036。
用户: quit
AI助手退出
文章来源:微信公众号-数智脉动,原始发表时间:2025年05月26日。