**多头注意力(Multi-Head Attention)**是对传统注意力机制的一种改进,旨在通过分割输入特征为多个“头部”(head)并独立处理每个头部来提高模型的表达能力和学习能力。多头注意力是 Transformer 模型的核心组件,能够并行学习输入序列不同位置之间的依赖关系。
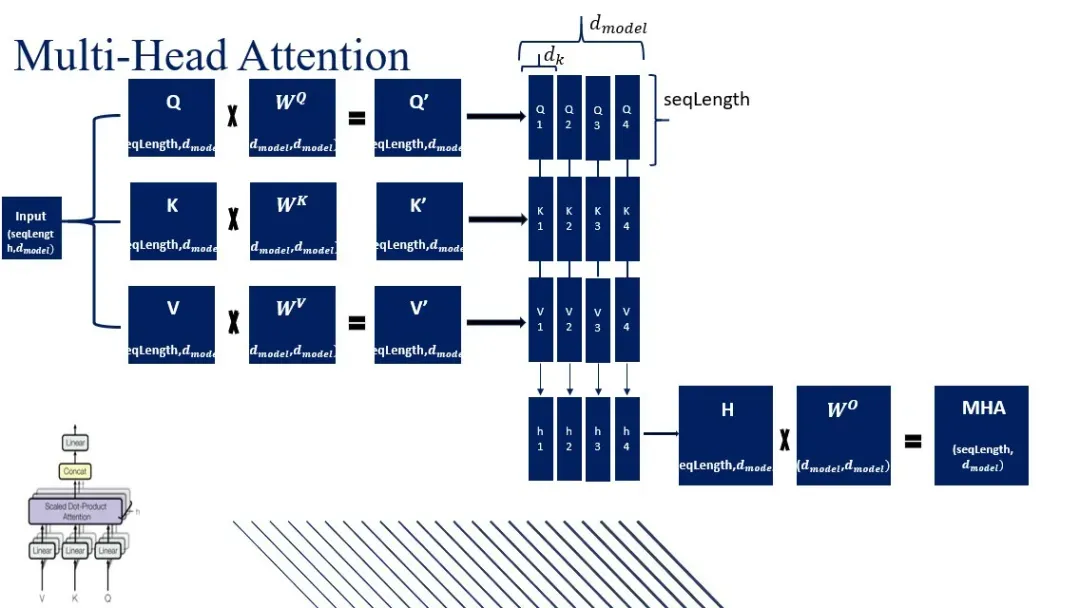
一、多头注意力
多头注意力(Multi-Head Attention)是什么?
多头注意力是将输入的特征(通常是查询、键和值)通过多个独立的、并行运行的注意力模块(或称为“头”)进行处理。
每个头都会独立地计算注意力得分,并生成一个注意力加权后的输出。这些输出随后被合并(通常是通过拼接或平均)以形成一个最终的、更复杂的表示。
多头注意力计算过程是什么?多头注意力将输入序列通过线性变换得到查询、键和值矩阵,然后分头进行缩放点积注意力运算,最后将所有头的输出拼接并经过线性变换得到最终输出。
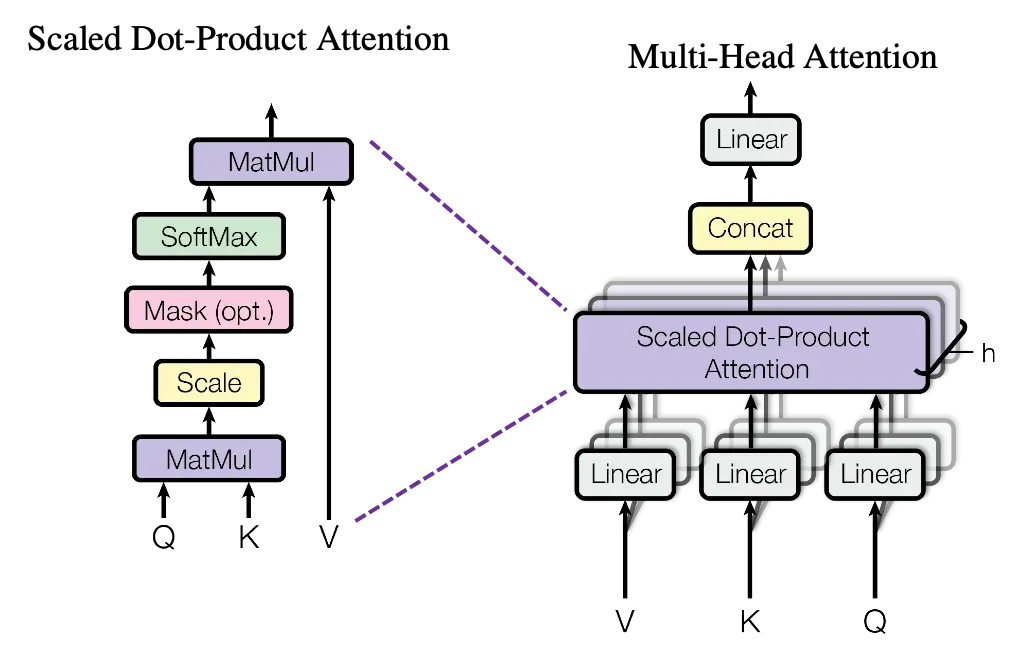
-
- 输入变换:通过三个不同的线性变换层,将输入映射到查询(Query)、键(Key)、值(Value)向量。
-
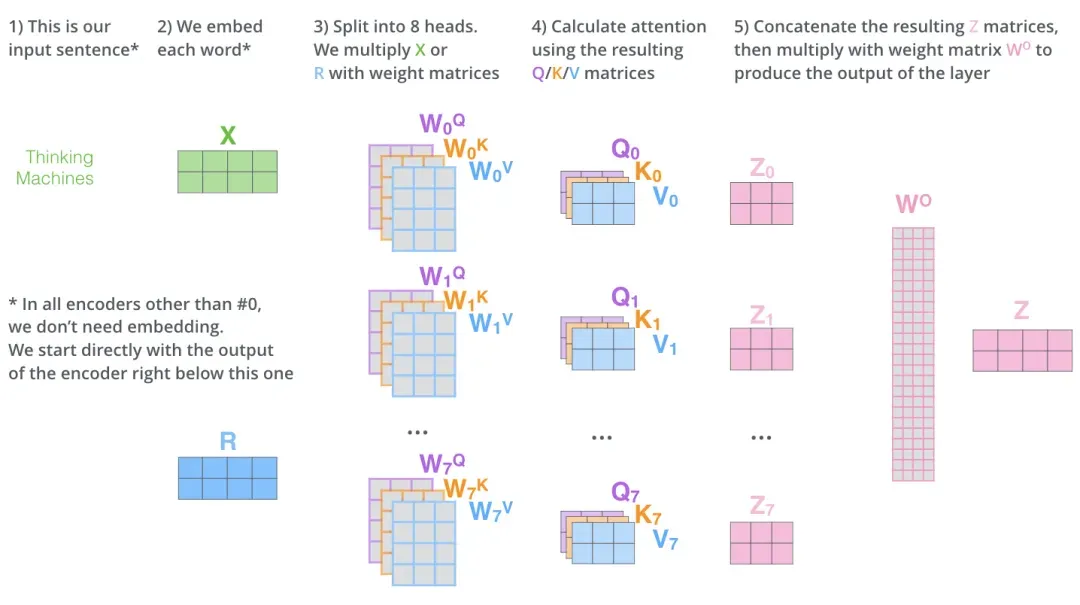
- 分割多头:将查询(Query)、键(Key)、值(Value)矩阵分成多个头,每个头具有不同的线性变换参数。
-
- 缩放点积注意力:对于每个头,都执行一次缩放点积注意力(Scaled Dot-Product Attention)运算。具体来说,计算查询和键的点积,经过缩放、加上偏置后,使用softmax函数得到注意力权重。
-
- 合并多头:将所有头的输出拼接在一起,形成一个长向量,对拼接后的向量进行一个最终的线性变换,以整合来自不同头的信息,得到最终的多头注意力输出。
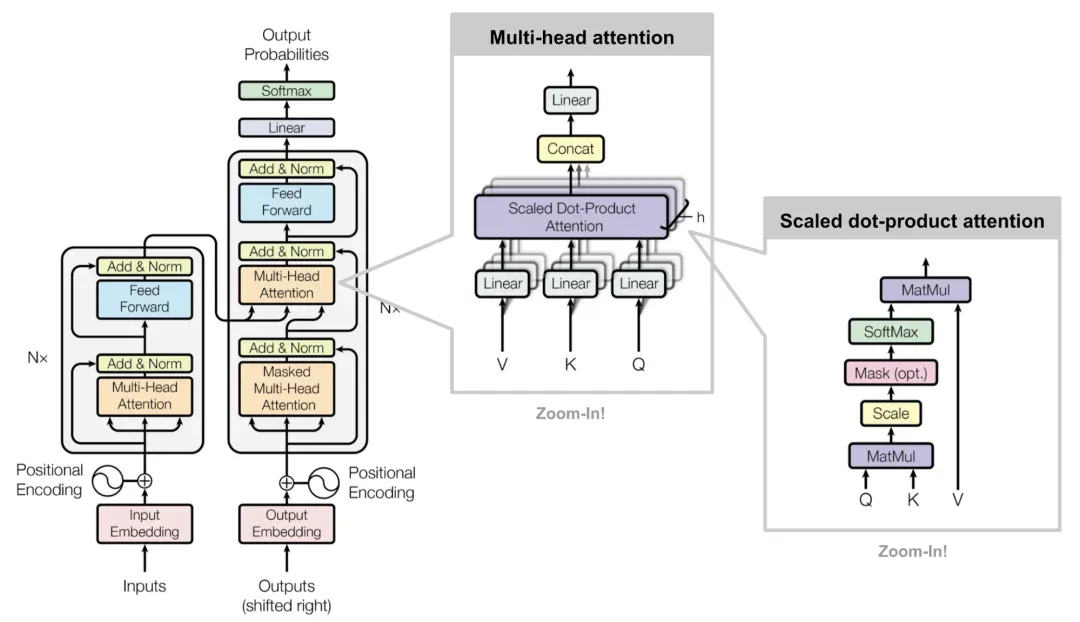
二、计算公式
多头注意力的计算公式是什么?
输入为一个向量序列X,包含n个元素,每个元素用d维向量表示。多头注意力的计算公式可以表示为:

import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, h, dropout=0.1):
"""
Args:
d_model: 输入维度(特征维度)
h: 注意力头的数量
dropout: Dropout 概率
"""
super().__init__()
self.d_model = d_model
self.h = h
self.d_k = d_model // h # 每个头的维度
# 定义线性变换层
self.W_q = nn.Linear(d_model, d_model) # 查询变换
self.W_k = nn.Linear(d_model, d_model) # 键变换
self.W_v = nn.Linear(d_model, d_model) # 值变换
self.W_o = nn.Linear(d_model, d_model) # 输出融合
self.dropout = nn.Dropout(dropout)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
计算缩放点积注意力
Args:
Q: 查询张量 (batch_size, h, seq_len, d_k)
K: 键张量 (batch_size, h, seq_len, d_k)
V: 值张量 (batch_size, h, seq_len, d_k)
mask: 掩码(可选)
"""
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
output = torch.matmul(attn_weights, V)
return output, attn_weights
def split_heads(self, x):
"""
将输入张量拆分为多头
Args:
x: 输入张量 (batch_size, seq_len, d_model)
"""
batch_size, seq_len, _ = x.size()
x = x.view(batch_size, seq_len, self.h, self.d_k) # 拆分为 h 个头
return x.transpose(1, 2) # (batch_size, h, seq_len, d_k)
def forward(self, Q, K, V, mask=None):
"""
Args:
Q: 查询张量 (batch_size, seq_len, d_model)
K: 键张量 (batch_size, seq_len, d_model)
V: 值张量 (batch_size, seq_len, d_model)
mask: 掩码(可选)
"""
batch_size = Q.size(0)
# 线性变换并拆分为多头
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# 计算注意力并合并多头
attn_output, attn_weights = self.scaled_dot_product_attention(Q, K, V, mask)
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 输出融合
output = self.W_o(attn_output)
return output, attn_weights