在人工智能与大数据蓬勃发展的今天,机器学习算法作为智能决策的核心引擎,正深刻改变着各行各业。从金融风控到医疗诊断,从图像识别到自然语言处理,这些算法构成了现代智能系统的基石。
本文将从数学原理、核心思想、应用场景三个维度,系统解析机器学习领域最具影响力的十大经典算法模型,揭示它们的技术本质与产业价值。
一、线性回归:连续值预测的基石
数学本质:通过最小化预测值与真实值的平方误差,建立特征与目标变量的线性关系:
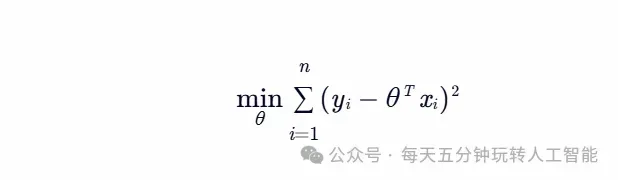
核心突破:解析解的存在使得计算效率极高,正则化项(L1/L2)可防止过拟合。 产业应用:房价预测、销量预估、用户生命周期价值建模等结构化数据预测场景。
二、逻辑回归:分类问题的概率视角
模型原理:将线性回归输出通过Sigmoid函数映射到(0,1)区间:
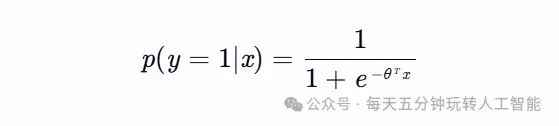
技术优势:输出概率解释性强,对数几率形式便于梯度优化。 典型场景:信用评分、广告点击率预测、疾病诊断等二分类任务。
三、决策树:可解释性建模的典范
构建过程:通过信息增益/基尼系数递归选择最优分割特征,生成树状决策规则。 算法特点:天然处理混合类型数据,特征重要性可解释性强。 工业实践:客户分群、规则引擎构建、风险因子分析等需要透明决策的场景。
四、随机森林:集成学习的抗过拟合利器
核心思想:Bootstrap采样构建多棵决策树,投票/平均法集成预测结果。 性能优势:降低方差提升泛化性,天然支持并行计算。 典型应用:金融反欺诈、图像分类、推荐系统排序模型。
五、支持向量机:高维空间的最优超平面
数学原理:通过核技巧将低维非线性问题映射到高维空间求解:
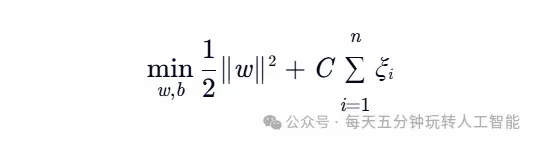
核函数选择灵活,小样本场景表现优异。
应用场景:文本分类、生物信息学、异常检测等复杂模式识别任务。
六、朴素贝叶斯:概率推理的简约之美
模型假设:特征条件独立假设下的贝叶斯定理应用:
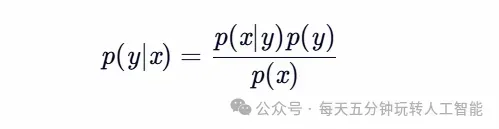
实践价值:训练速度快,适合高维稀疏数据(如文本)。 典型应用:垃圾邮件过滤、情感分析、推荐系统冷启动。
七、K近邻:局部模式的距离感知
算法逻辑:基于样本特征空间的距离度量(欧氏/曼哈顿)进行局部预测。 关键参数:K值选择影响偏差-方差平衡,需标准化处理特征。 应用场景:图像识别、推荐系统、异常检测等局部模式敏感任务。
八、神经网络:深度学习的非线性引擎
模型结构:多层感知机通过非线性激活函数(ReLU/Sigmoid)学习复杂映射:
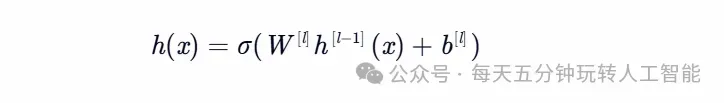
技术优势:自动特征学习,大规模数据下表现卓越。 产业革命:计算机视觉、自然语言处理、语音识别等领域的突破性进展。
九、梯度提升树(XGBoost):结构化数据的王者
核心机制:通过迭代训练弱学习器(决策树),利用梯度下降优化损失函数。 工程优化:支持类别特征处理,训练速度比传统GBDT提升数倍。 工业地位:Kaggle竞赛常胜模型,广泛应用于金融风控、广告排序等场景。
十、K均值聚类:无监督学习的原型发现
算法流程:迭代优化样本到聚类中心的距离平方和:
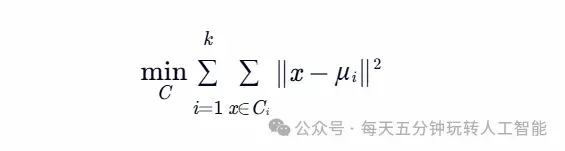
实践挑战:初始中心敏感,需结合轮廓系数评估聚类质量。 典型应用:客户细分、图像压缩、异常检测等无标签数据挖掘场景。
算法生态协同与未来趋势
这些核心算法并非孤立存在,而是通过集成学习(如GBDT+深度学习)、自动化机器学习(AutoML)等技术形成协同生态。未来发展趋势呈现三大方向:
-
混合架构:将传统算法的可解释性与深度学习的表征能力结合(如Wide & Deep模型)
-
自动化优化:通过神经架构搜索(NAS)自动设计模型结构
-
联邦学习:在隐私保护前提下实现分布式模型训练
文章来源:微信公众号-每天五分钟玩转人工智能,原始发表时间:2025年03月18日。