导读
Transformer模型以其卓越的性能和广泛的应用成为了新一代的领航者。这篇文章将带您深入探索Transformer模型的奥秘,从基础的注意力机制到复杂的编码器-解码器架构,再到多头注意力和位置编码的巧妙融合。无论您是AI领域的新手还是资深研究者,都能通过本文获得对Transformer模型深刻的理解和认识。
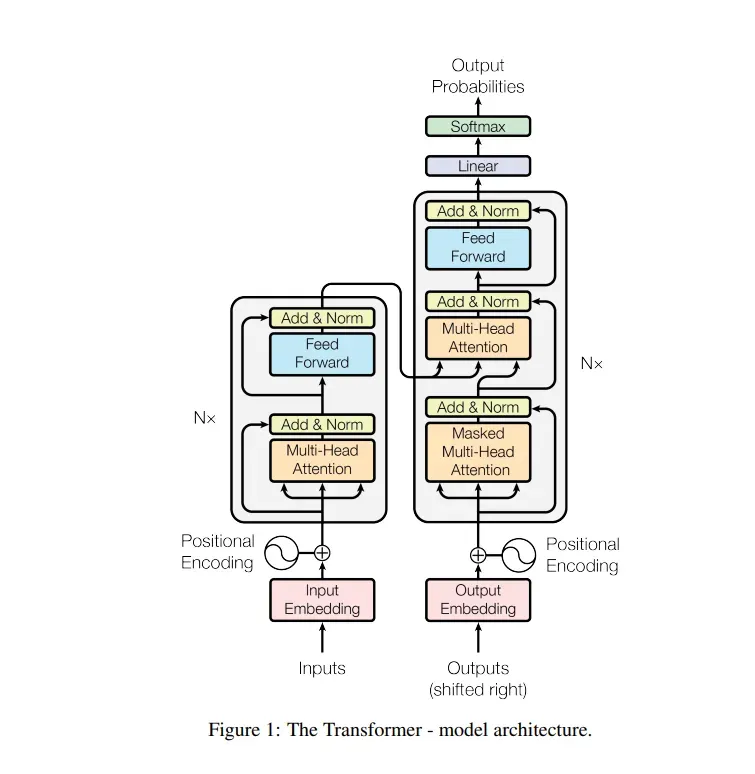
Transformer模型自2017年由Google的研究团队提出以来,已经成为自然语言处理(NLP)领域的主流模型。它的核心优势在于能够处理序列数据,并且摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)的顺序处理方式,这使得Transformer在处理长序列数据时具有更高的并行性和更好的性能。Transformer模型的提出,不仅在机器翻译、文本生成、情感分析等多个NLP任务中展现出卓越的性能,而且其变体和衍生模型如BERT、GPT等也在各种任务中取得了突破性进展。
Transformer模型的核心优势在于其自注意力机制和并行计算能力。自注意力机制允许模型在处理序列数据时,能够同时关注序列中的所有位置,捕捉长距离依赖关系。此外,由于自注意力机制的计算可以并行进行,Transformer模型能够充分利用现代GPU和TPU的并行计算能力,加快训练速度。这一点在处理大规模数据集时尤为明显,使得模型能够在短时间内学习到更多的数据特征。
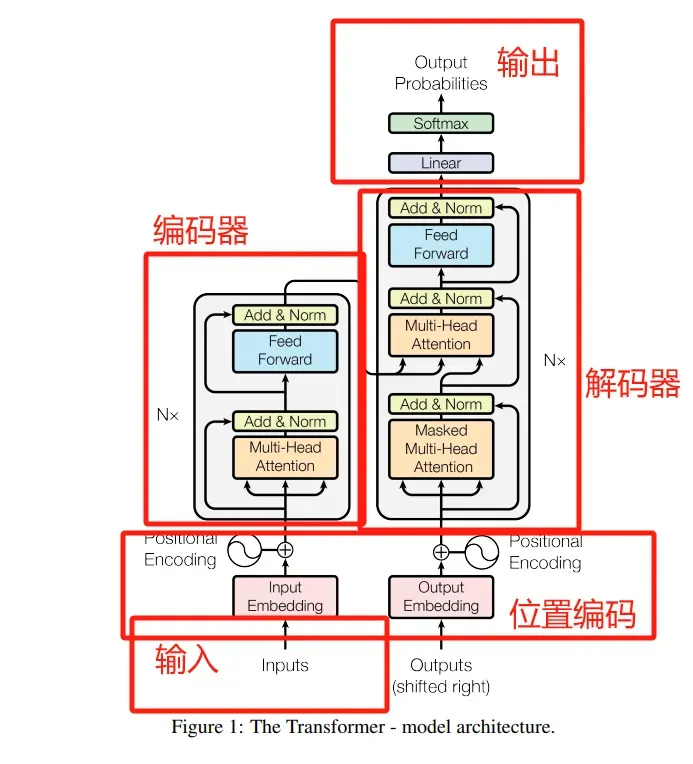
**Transformer模型的基本架构由编码器(Encoder)和解码器(Decoder)两部分组成。**编码器负责将输入序列转换为一系列高维表示,而解码器则基于这些表示生成输出序列。在编码器和解码器内部,都堆叠了多个相同的层,每层包含自注意力子层和前馈神经网络子层,以及用于正则化的层归一化和残差连接。下面我们逐一拆解Transformer模型。
1、输入表示
1.1 单词嵌入
在Transformer模型中,输入序列的每个单词首先需要通过单词嵌入层转换为高维向量。这一步骤是模型理解输入数据的基础,单词嵌入的质量直接影响到模型的性能。
-
嵌入维度
Transformer模型通常使用维度为512或768的单词嵌入,这意味着每个单词将被映射到一个512或768维的向量空间中。这样的高维空间能够捕捉到丰富的语义信息和语法结构。
-
预训练与微调
在实际应用中,单词嵌入向量可以是预训练的,也可以在特定任务上进行微调。预训练的嵌入向量能够捕捉通用的语言模式,而微调则使模型能够适应特定的任务或领域。
-
词汇表覆盖
Transformer模型的词汇表通常包含数十万的词汇量,足以覆盖大多数语言现象。对于词汇表外的词(OOV),可以通过特殊的标记如“UNK”来处理。
-
下一句预测
在BERT等预训练模型中,单词嵌入还涉及到下一句预测(Next Sentence Prediction, NSP)的任务,这要求模型能够理解句子间的关系,进一步提升了模型的语言理解能力。
1.2 位置编码
位置编码(Positional Encoding)在Transformer模型中扮演着至关重要的角色,其必要性主要体现在以下几个方面:
- 捕捉序列顺序信息:Transformer模型由于其架构的特性,缺乏对序列中元素顺序的内在感知能力。位置编码通过为序列中的每个元素提供位置信息,使模型能够区分元素的顺序,从而捕捉到序列中的时序动态和语义关系。
- 增强模型表达能力:位置编码使得模型能够利用位置信息来增强其表达能力,尤其是在处理语言任务时,词语的顺序对于理解句子的语义至关重要。通过位置编码,模型可以更好地理解句子结构和语境。
- 改善长距离依赖问题:在长序列处理中,位置编码帮助模型识别远距离的依赖关系,这对于语言模型来说尤为重要,因为语言中的修饰关系和指代关系往往跨越较远的距离。
- 提升模型泛化能力:位置编码使得模型在面对不同长度的输入序列时,能够保持稳定的性能。这对于模型在实际应用中的泛化能力至关重要,因为输入数据的长度往往是多变的。
位置编码的实现方式多样,但最常用的方法是正弦和余弦函数的固定位置编码,其具体实现如下:
-
正弦和余弦函数
Transformer模型使用正弦和余弦函数的不同频率来为序列中的每个位置生成唯一的编码。具体来说,位置编码的第i个维度的值由以下公式确定:
PE(pos,2i)=sin(pos100002i/dmodel)
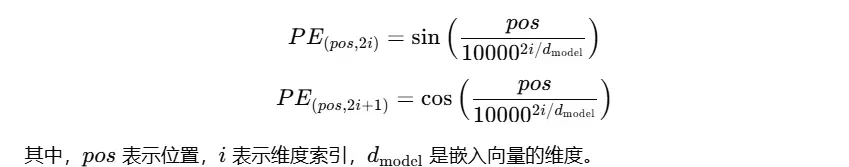
- 编码生成:根据上述公式,可以为每个位置生成一个位置编码向量,然后将该向量添加到对应的词嵌入向量中。这样,每个词嵌入向量不仅包含了词汇本身的语义信息,还包含了其在序列中的位置信息。
- 编码优势:这种基于三角函数的位置编码方法具有多个优点,包括能够适应任意长度的序列、易于计算和扩展,以及能够捕捉到相对位置信息。
- 其他实现方式:除了正弦-余弦位置编码,还有其他实现位置编码的方法,如可学习的位置编码,即模型在训练过程中学习位置编码向量。这种方法允许模型自适应地从数据中学习位置信息,但需要更多的参数和计算资源。
-
周期性
位置编码的周期性使得模型能够捕捉到单词之间的相对距离。例如,如果两个单词的位置编码在某个维度上的正弦值相等,则它们在该维度上的相对距离是相同的。
-
相加操作
位置编码向量与单词嵌入向量直接相加,形成最终的输入表示。这种简单而有效的方式使得模型在处理输入序列时能够同时考虑到单词的语义信息和位置信息。
-
灵活性
虽然Transformer模型最初使用固定的正弦余弦位置编码,但后续的研究提出了可学习的位置编码,允许模型在训练过程中自动学习最优的位置表示。这种方法为处理不同长度的序列提供了更大的灵活性。
2、编码器(Encoder)
2.1 编码器架构
编码器作为Transformer模型的核心组件之一,其架构设计对于模型性能至关重要。编码器由多个相同的层(stacked layers)组成,每层都包含多头自注意力机制和前馈神经网络,以及用于正则化的层归一化和残差连接。
-
层数配置
标准的Transformer模型中,编码器由6个相同的层组成,每个层都能够独立地处理输入序列的不同方面,从而学习到丰富的特征表示。
-
残差连接与层归一化
每个子层(自注意力层和前馈神经网络层)的输出都会与输入进行相加(残差连接),然后通过层归一化。这种设计有助于缓解深度网络中的梯度消失问题,使得深层网络的训练变得更加稳定。
2.2 多头自注意力(Multi-Head Self-Attention)
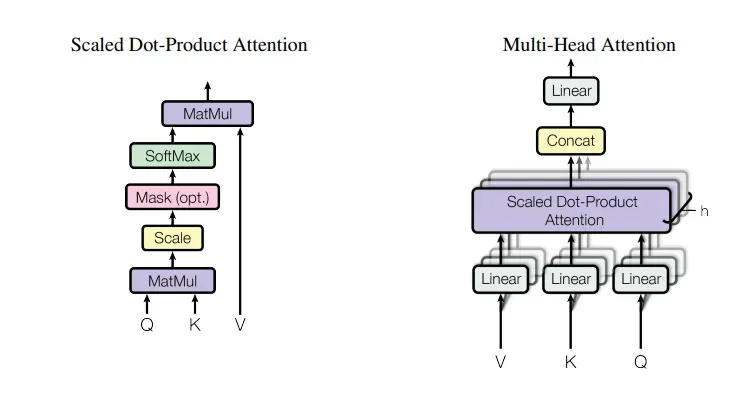
多头自注意力机制是Transformer模型中的关键创新之一,它允许模型同时关注序列中的不同部分,捕捉词与词之间的复杂关系。
多头注意力机制是自注意力机制的扩展,它通过并行地进行多个自注意力计算,使得模型能够同时从不同的表示子空间中捕捉信息。
-
结构:在多头注意力中,输入序列被映射到多个不同的表示空间,每个表示空间都进行一次自注意力计算。这些表示空间的输出然后被拼接在一起,并通过一个线性层进行融合,得到最终的输出。
-
优势:多头注意力机制能够捕捉到不同子空间中的信息,这使得模型能够学习到更加丰富的特征表示。例如,在一个表示空间中模型可能学习到语法结构,而在另一个表示空间中可能学习到语义信息。
-
实现:多头注意力的实现涉及到将输入序列通过多个W^Q、W^K、W^V矩阵进行线性变换,每个矩阵对应一个“头”。然后,每个头的输出被拼接在一起,并通过一个线性层进行融合。这种结构使得模型能够并行处理多个注意力计算,提高了计算效率。
-
头数分配
在标准的Transformer模型中,多头自注意力机制通常分为8个独立的头,每个头学习输入序列的不同表示子空间。
-
自注意力计算
每个头都会独立地计算查询(Q)、键(K)和值(V)的表示,并通过缩放点积操作来计算注意力分数。这些分数随后通过softmax函数进行归一化,得到每个头的注意力权重。
-
信息融合
每个头输出的加权值向量会被拼接在一起,并通过一个线性层进行变换,以融合来自不同头的信息。
2.3 前馈网络(Feed Forward Network)
前馈网络(Feed Forward Network,FFN)是Transformer模型中的一个重要组件,它在每个编码器(Encoder)和解码器(Decoder)层中都会出现。FFN的结构相对简单,但承担着重要的角色,即对序列中的每个元素进行非线性变换和映射。
FFN通常由两个线性变换组成,中间夹着一个非线性激活函数。具体来说,FFN的结构可以表示为:

在Transformer模型中,FFN的输入是自注意力机制的输出,输出则会被送回到自注意力机制中,与输入进行残差连接和层归一化。这种结构使得FFN能够对自注意力机制的输出进行进一步的非线性处理,增强模型的表达能力。
- **维度变换:**前馈网络的第一个线性层将输入从维度dmodel映射到一个更高维度的空间,第二个线性层再将其映射回原始维度。这种设计使得网络能够学习到更复杂的函数映射。
- **参数共享:**在每个编码器层中,前馈网络的权重是共享的,这意味着每一层都使用相同的参数来处理不同的输入序列。这有助于模型学习到更加通用的特征表示。
2.4 残差连接与层归一化
2.4.1残差连接原理
残差连接(Residual Connection)是Transformer模型中一个至关重要的组件,其核心思想是解决深层网络训练中的梯度消失和梯度爆炸问题,同时提高模型的训练效率和性能。
- 基本原理:残差连接通过将每个子层(sub-layer)的输入直接添加到其输出上,从而构建了一个恒等映射(identity mapping)。这种设计允许模型在每个层中学习到的不仅仅是数据的变换,还包括恒等变换本身。数学上,如果H(x)是某个子层的输出,xx是输入,则残差连接的输出为F(x)+x,其中F(x)是除了恒等映射外的变换部分。
- 梯度流动:在反向传播过程中,残差连接提供了一个直接的路径,使得梯度可以不受阻碍地从输出端流回输入端。这种设计显著减少了梯度在深层网络中传播时的衰减,从而缓解了梯度消失问题。
- 网络深度:残差连接使得网络可以更容易地增加深度,而不会因为梯度问题而导致性能下降。实验表明,即使网络深度达到数千层,残差连接也能保持稳定的性能。
- 实现细节:在实际实现中,当输入和输出的维度不一致时,通常会引入一个额外的线性层(称为“shortcut connection”或“skip connection”),以确保残差连接的输入和输出维度匹配,从而可以直接相加。
2.4.2层归一化作用
层归一化(Layer Normalization)是Transformer模型中另一个重要的组件,它通过对每个层的激活值进行归一化,有助于稳定训练过程并提高模型的性能。
- 归一化过程:层归一化通过对每个样本的所有特征进行归一化,使得每个层的输出都具有相同的分布。具体来说,对于每个层的输出Z,层归一化计算出其均值μ和标准差σ,然后对每个特征进行归一化处理:Z^=Z−μσ
- 减少内部协变量偏移:层归一化通过规范化操作减少了内部协变量偏移(Internal Covariate Shift),即神经网络层输入分布的变化。这有助于加速模型的收敛,并使得模型对初始化和学习率的选择更加鲁棒。
- 并行处理:与批量归一化(Batch Normalization)不同,层归一化不依赖于批次(batch)的数据,因此可以很容易地应用于并行处理的场景,如Transformer模型中的自注意力机制。
- 提高模型性能:层归一化有助于提高模型的性能,因为它使得每一层的输出更加稳定,减少了过拟合的风险。此外,它还可以作为正则化的一种形式,进一步提高模型的泛化能力。
- 实现细节:在实际应用中,层归一化通常在每个子层(如自注意力层和前馈网络层)之后应用,并且在残差连接之前。这样,归一化的输出可以直接与子层的输入相加,然后通过激活函数进行非线性变换。
通过这种精心设计的编码器架构,Transformer模型能够有效地处理序列数据,捕捉长距离依赖关系,并为下游任务提供丰富的特征表示。
3. 解码器(Decoder)
3.1 解码器架构
解码器在Transformer模型中扮演着将编码器的输出转换为最终输出序列的关键角色。解码器的架构与编码器相似,但包含了额外的注意力机制,以确保生成的输出序列与输入序列保持一致性。
-
层数配置
与编码器相同,标准的Transformer模型中,解码器也由6个相同的层组成。每层包含自注意力层、编码器-解码器注意力层和前馈神经网络层,以及残差连接和层归一化。
-
自回归特性
解码器在生成输出时采用自回归的方式,即在每一步只依赖于之前生成的输出,而不依赖于未来的输出。这保证了解码器在处理序列数据时的因果关系。
3.2 掩码多头自注意力(Masked Multi-Head Self-Attention)
掩码多头自注意力机制是解码器中的第一个关键组件,它确保了解码器在生成每个单词时只能看到之前的位置,而不能“窥视”未来的信息。
-
掩码操作
在自注意力计算中,通过掩码操作将未来位置的注意力分数设置为一个非常大的负数(通常是负无穷),这样在应用softmax函数时,这些位置的权重就会接近于零,从而不会对当前位置的输出产生影响。
-
防止信息泄露
掩码多头自注意力机制有效地防止了信息泄露问题,即在生成当前单词时不会利用到未来的单词信息,这对于保持序列生成任务的合理性和准确性至关重要。
-
性能影响
掩码操作使得解码器在每个时间步都必须独立地处理,从而牺牲了一定的并行化能力。然而,这对于保持解码器的自回归特性和生成合理的输出序列是必要的。
3.3 编码器-解码器注意力(Encoder-Decoder Attention)
编码器-解码器注意力机制是解码器中的第二个关键组件,它允许解码器关注编码器的输出,从而将输入序列的信息融入到输出序列中。
-
注意力计算
在编码器-解码器注意力层中,解码器的查询(Q)与编码器的键(K)和值(V)进行交互,计算出注意力分数,并通过softmax函数进行归一化。
-
信息融合
通过这种注意力机制,解码器能够聚焦于编码器输出中与当前生成任务最相关的部分,从而有效地利用输入序列的信息来指导输出序列的生成。
-
增强模型表现
编码器-解码器注意力机制显著增强了模型在处理复杂序列到序列任务时的表现,特别是在机器翻译和文本摘要等任务中,它使得模型能够更好地理解和利用输入序列的结构和内容。
通过上述解码器的详细图解和分析,我们可以看到Transformer模型如何通过精巧的结构设计来处理序列数据,并生成高质量的输出序列。解码器的掩码多头自注意力和编码器-解码器注意力机制共同确保了模型在生成输出时能够有效地利用输入序列的信息,同时保持输出序列的合理性和准确性。
4. 逐层模块图解
4.1 编码器层图解
Transformer模型的编码器层是理解整个模型的关键。下面我们将逐层图解编码器的结构和信息流动。
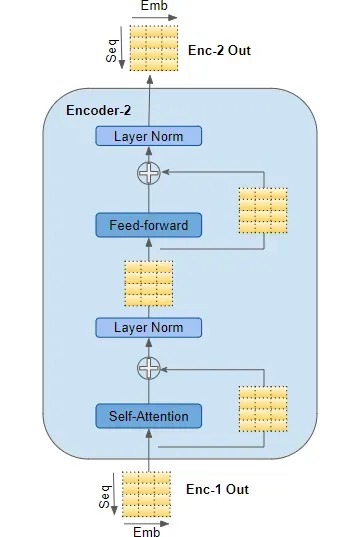
**编码器层结构:**编码器的每一层由三个主要模块组成:多头自注意力模块、前馈神经网络模块,以及残差连接和层归一化。这些模块共同工作,将输入序列转换为一系列高维表示。
- 多头自注意力模块:
- 包含8个注意力头,每个头学习输入序列的不同表示子空间。
- 通过计算查询(Q)、键(K)和值(V)的点积注意力,捕捉序列内部的依赖关系。
- 使用缩放因子(通常是维度的平方根)来防止softmax函数的数值不稳定。
- 前馈神经网络模块:
- 包含两个线性变换,中间通过ReLU激活函数引入非线性。
- 第一个线性层将维度从dmodel映射到4倍的维度,第二个线性层再将其映射回原始维度。
- 残差连接和层归一化:
- 每个子层的输出加上其输入(残差连接),然后进行层归一化。
- 层归一化对每一层的激活值进行归一化,有助于加速训练并提高模型稳定性。
**编码器层间信息流动:**编码器的每一层都会接收前一层的输出作为输入,并输出一系列高维表示,这些表示会被传递到下一层。这种堆叠结构使得模型能够逐层抽象和提取输入序列的特征。
4.2 解码器层图解
解码器层的结构与编码器类似,但包含额外的注意力机制,以确保生成的输出序列与输入序列保持一致性。
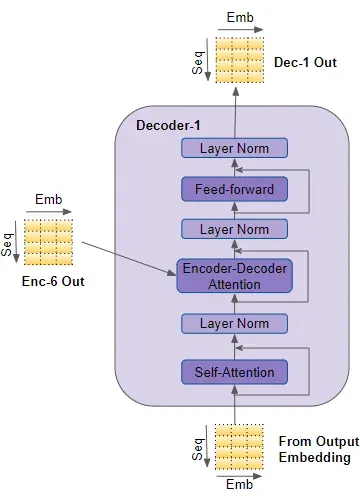
**解码器层结构:**解码器的每一层由四个主要模块组成:掩码多头自注意力模块、编码器-解码器注意力模块、前馈神经网络模块,以及残差连接和层归一化。
- 掩码多头自注意力模块:
- 通过掩码操作防止解码器在生成当前单词时看到未来的单词。
- 确保解码器的自回归特性,即每一步只依赖于之前生成的输出。
- 编码器-解码器注意力模块:
- 解码器的查询(Q)与编码器的键(K)和值(V)进行交互,计算出注意力分数。
- 使解码器能够聚焦于编码器输出中与当前生成任务最相关的部分。
- 前馈神经网络模块:
- 与编码器中的前馈网络结构相同,包含两个线性变换和ReLU激活函数。
- 残差连接和层归一化:
- 与编码器中的操作相同,每个子层的输出加上其输入,然后进行层归一化。
**解码器层间信息流动:**解码器的每一层都会接收来自编码器的编码信息以及之前层的输出,生成一系列高维表示,这些表示会被传递到下一层,并最终用于生成输出序列。
4.3 层间连接与信息流动
在Transformer模型中,层间的连接和信息流动是模型能够有效处理序列数据的关键。
- 编码器层间连接:
- 每一层的输出作为下一层的输入,形成了一个序列到序列的映射。
- 层间的残差连接和层归一化确保了信息的流动和模型的稳定性。
- 解码器层间连接:
- 解码器层间的连接与编码器类似,但增加了掩码多头自注意力模块,以保持输出序列的自回归特性。
- 层间的信息流动同样通过残差连接和层归一化进行,确保了生成过程中信息的完整性和稳定性。
- 编码器-解码器连接:
- 解码器层的编码器-解码器注意力模块连接了编码器和解码器,实现了信息的交互。
- 这种连接使得解码器能够利用编码器的输出信息,生成与输入序列一致的输出序列。
通过上述图解和分析,我们可以清晰地看到Transformer模型中信息是如何在各个层之间流动和转换的,以及每个模块如何协同工作以实现高效的序列处理和特征提取。
5. 训练与评估
5.1 训练过程
Transformer模型的训练过程涉及多个关键步骤,包括数据预处理、模型参数初始化、前向传播、损失计算、反向传播和参数更新。
- 数据预处理:在训练之前,需要对输入数据进行预处理,包括文本清洗、分词、词嵌入等。对于Transformer模型,还需要生成位置编码,以保留文本的顺序信息。
- 模型参数初始化:Transformer模型包含大量的参数,包括词嵌入矩阵、位置编码矩阵、自注意力机制中的查询(Q)、键(K)和值(V)的权重矩阵,以及前馈网络的权重。这些参数通常随机初始化,并在训练过程中进行调整。
- 前向传播:在前向传播阶段,输入数据通过Transformer模型的编码器和解码器层进行处理。每个编码器层包含自注意力机制和前馈网络,而每个解码器层包含掩码自注意力机制、编码器-解码器注意力机制和前馈网络。通过这些层的处理,模型生成输出序列。
- 损失计算:Transformer模型通常用于序列到序列的任务,如机器翻译。在这些任务中,模型的输出与目标序列之间的差异通过损失函数进行量化。常用的损失函数包括交叉熵损失,它衡量模型预测的概率分布与实际标签之间的差异。
- 反向传播:损失函数的梯度通过反向传播算法计算,从输出层向输入层逐层传播。在这个过程中,每个参数的梯度都被计算出来,以便于更新参数。
- 参数更新:使用梯度下降或其变体(如Adam优化器)根据计算出的梯度更新模型参数。学习率控制着参数更新的步长。
- 训练策略:为了提高训练效率和模型性能,可以采用多种训练策略,如梯度裁剪防止梯度爆炸、学习率衰减、早停法等。
5.2 评估指标
评估Transformer模型的性能时,常用的指标包括精确率、召回率、F1值、准确率和交叉熵损失等。
- 精确率(Precision):精确率衡量模型预测为正类的样本中,真正为正类的比例。它反映了模型预测的准确性。
- 召回率(Recall):召回率衡量真实为正类的样本中,被模型正确预测为正类的比例。它反映了模型的覆盖能力。
- F1值(F1 Score):F1值是精确率和召回率的调和平均数,综合了两者的优点,是评估模型整体性能的重要指标。
- 准确率(Accuracy):准确率衡量模型预测正确的样本数占总样本数的比例。它是一个直观的评价指标,但在处理类别不平衡问题时效果不理想。
- 交叉熵损失(Cross-Entropy Loss):交叉熵损失衡量模型预测的概率分布与实际标签之间的差异。交叉熵损失越小,表示模型的预测越准确。
在实际应用中,需要结合具体任务和数据特点,选择合适的指标进行评估。例如,在机器翻译任务中,除了准确率和交叉熵损失外,还可以使用BLEU(Bilingual Evaluation Understudy)分数来评估翻译质量。BLEU分数通过比较机器翻译输出与人类翻译的重合度来衡量翻译的好坏。
文章来源:微信公众号-智驻未来,原始发表时间:2024年12月16日。