导读
谷歌近期开源了Gemma 系列新成员Gemma 3,它是一个多模态模型,参数规模从1B 到27B,引入了视觉理解能力、更广泛的语言覆盖范围和128K 上下文,还显著提高了数学、聊天、指令跟随和多语言能力,使 Gemma3-4B-IT 在基准测试中与Gemma2-27B-IT 竞争,并与Gemini-1.5-Pro 相媲美。
Gemma 3
核心看点:
-
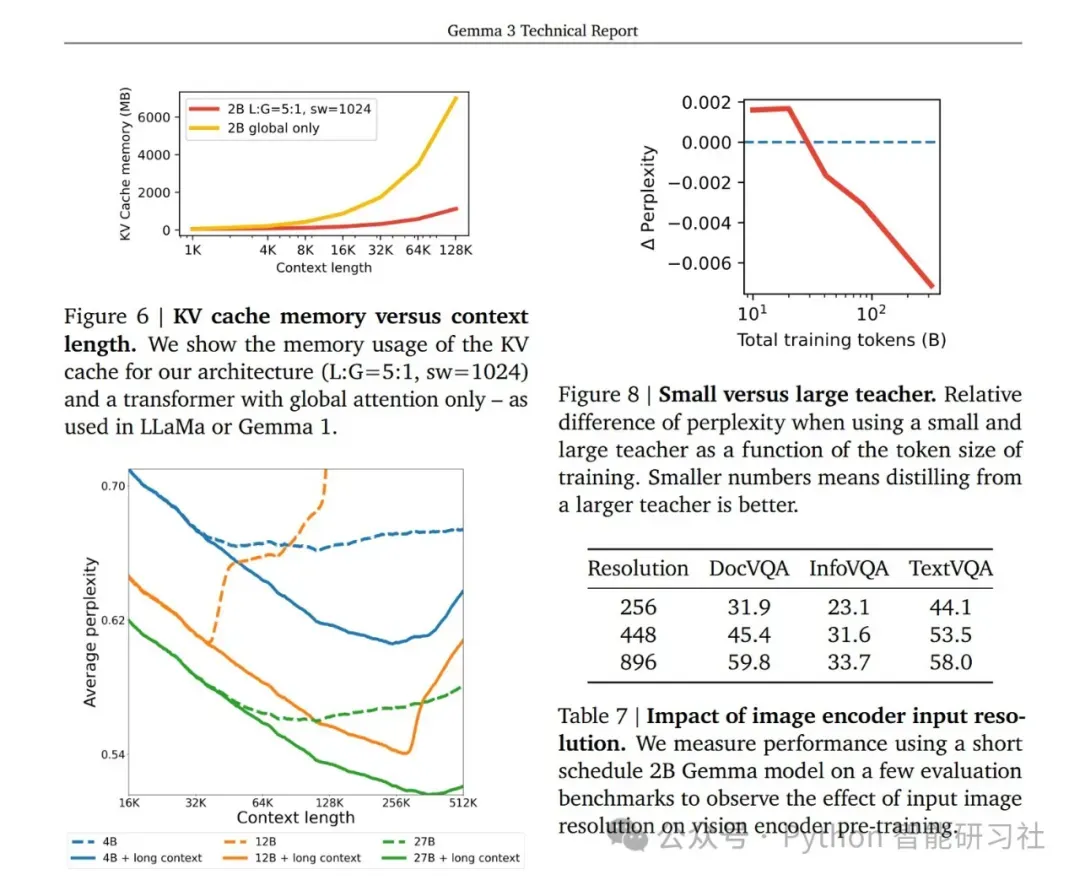
架构创新:为了应对长上下文带来的KV-cache 内存爆炸问题,Gemma 3 采用了局部注意力层和全局注意力层交错的架构。具体来说,模型在每5 个局部层后插入一个全局层,并且局部层的注意力跨度被限制在1024 个 tokens。这种设计使得只有全局层需要处理长上下文,显著降低了内存需求,同时保持了模型处理长序列的能力,架构改进是Gemma 3 能够支持128K 上下文长度的关键。
-
多模态能力:Gemma 3 引入了多模态能力,用了一个400M 的基于SigLIP 变种视觉编码器(ViT 架构,用CLIP loos 变种进行训练),将图像编码为一系列软tokens,并将其输入到语言模型中进行处理。为了降低图像处理的推理成本,视觉embeddings 被压缩成固定大小的256 个token。此外,为了处理不同分辨率图像,Gemma 3 借鉴LLaVA 的思想,采用了Pan & Scan (P&S) 方法,可以在推理时自适应地将图像分割成多个重叠的crops,然后分别编码,从而处理非方形宽高比和高分辨率图像,解决文本不可读或小物体消失问题。
-
知识蒸馏&强化学习微调:Gemma 3 采用了新颖的后训练方法,核心是结合了知识蒸馏和强化学习微调,显著提升了模型在数学、聊天、指令跟随和多语言任务上的性能。首先,利用大型指令微调教师模型进行知识蒸馏,将教师模型的知识迁移到Gemma 3 学生模型上。然后,采用基于强化学习的微调方法,结合多种奖励函数,包括人类反馈奖励模型、代码执行反馈和数学问题求解的ground-truth 奖励,进一步提升模型性能和安全性。这种综合性的后训练方法是 Gemma 3 性能大幅提升的关键。
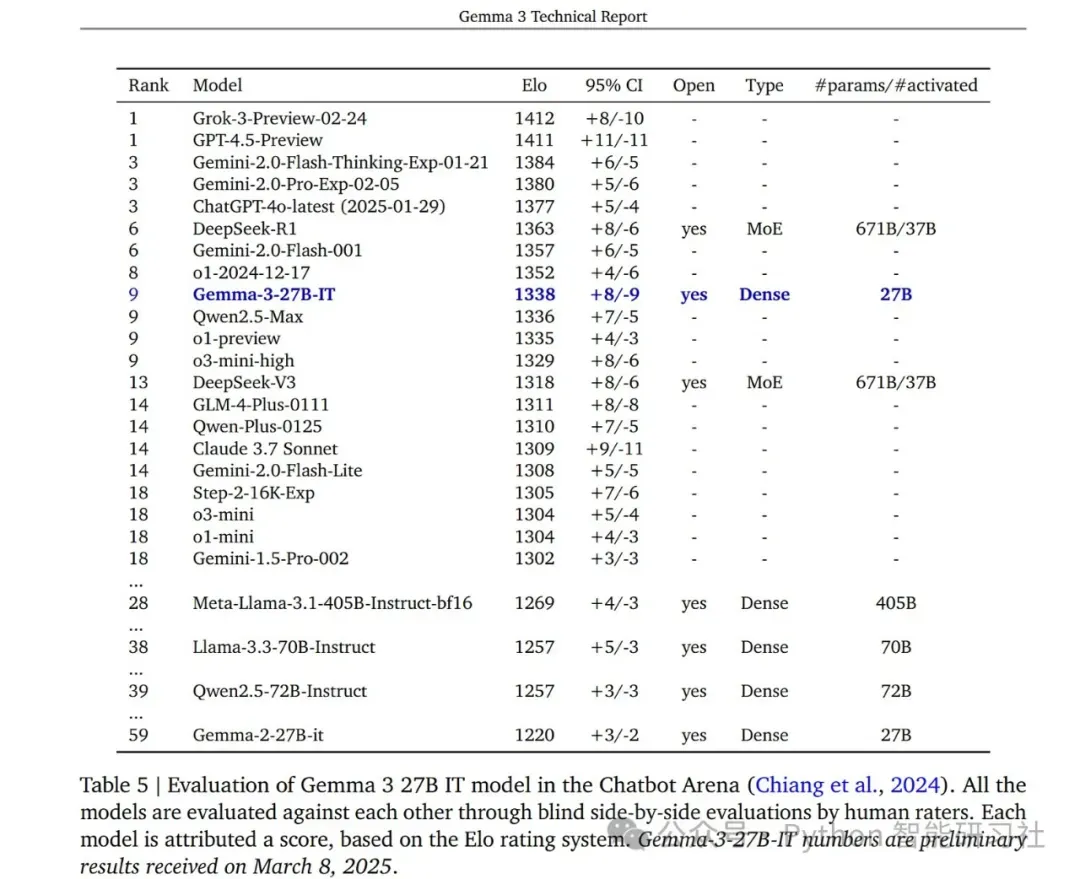
关键数据:
- LMSYS Chatbot Arena Elo 评分 (Gemma 3 27B IT):1338,排名前十,高于其他非思维型开源模型。
- KV-cache 内存占用 (32K 上下文长度): 相比”global only” 配置,采用 L:G=5:1, sw=1024 架构, KV-cache 内存占用显著降低。
总结
蒸馏学习+强化学习大法好啊,自DeepSeek 这一波儿玩得大放异彩后,各家也是纷纷上马,直接让20B-50B 这个参数规模的模型有了媲美更大规模大模型的性能,对于落地着实利好。
引用:
- Gemma 3 Technical Report:https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf
文章来源:微信公众号-Python 智能研习社,原始发表时间:2025年03月28日。